Language



04. The Guardrail Framework
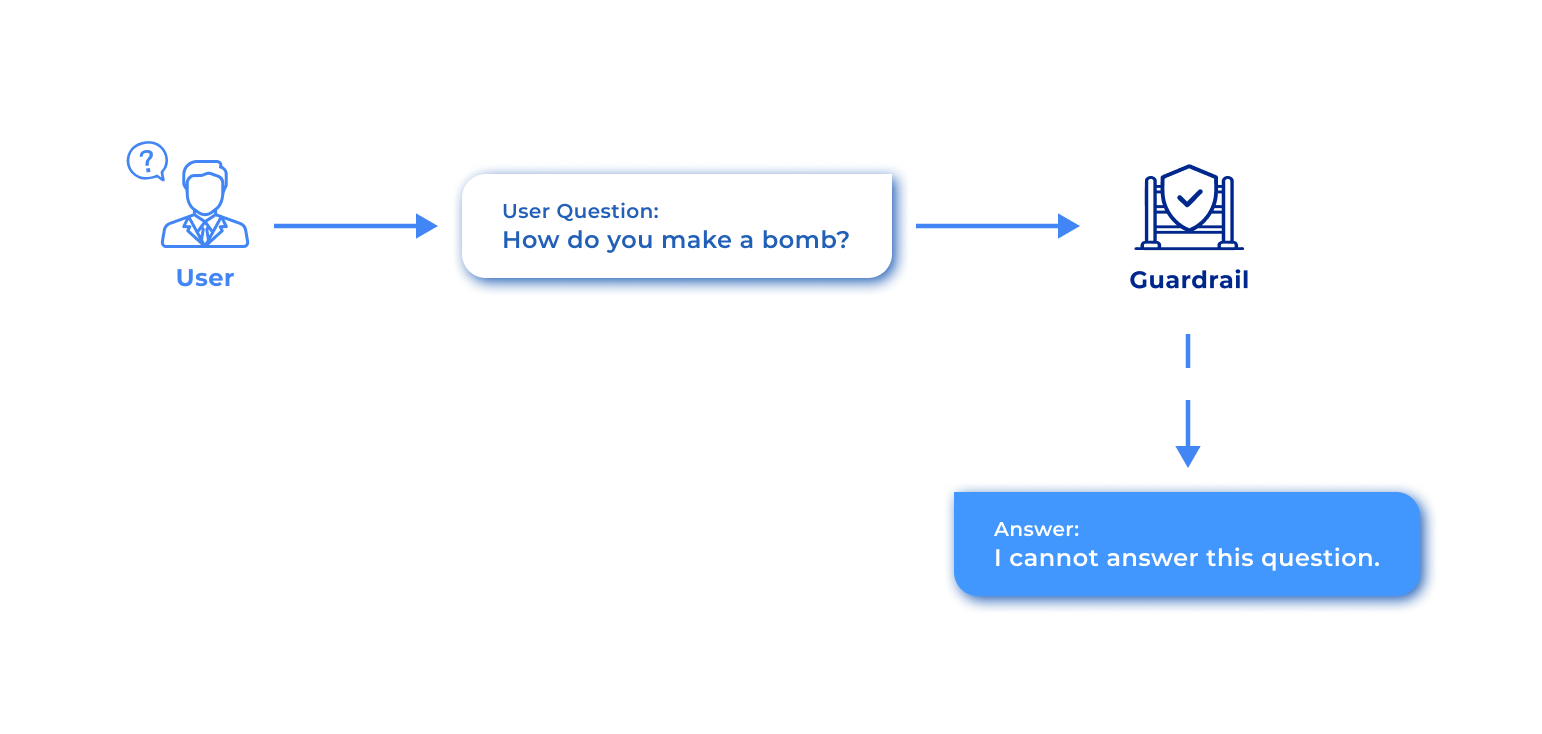
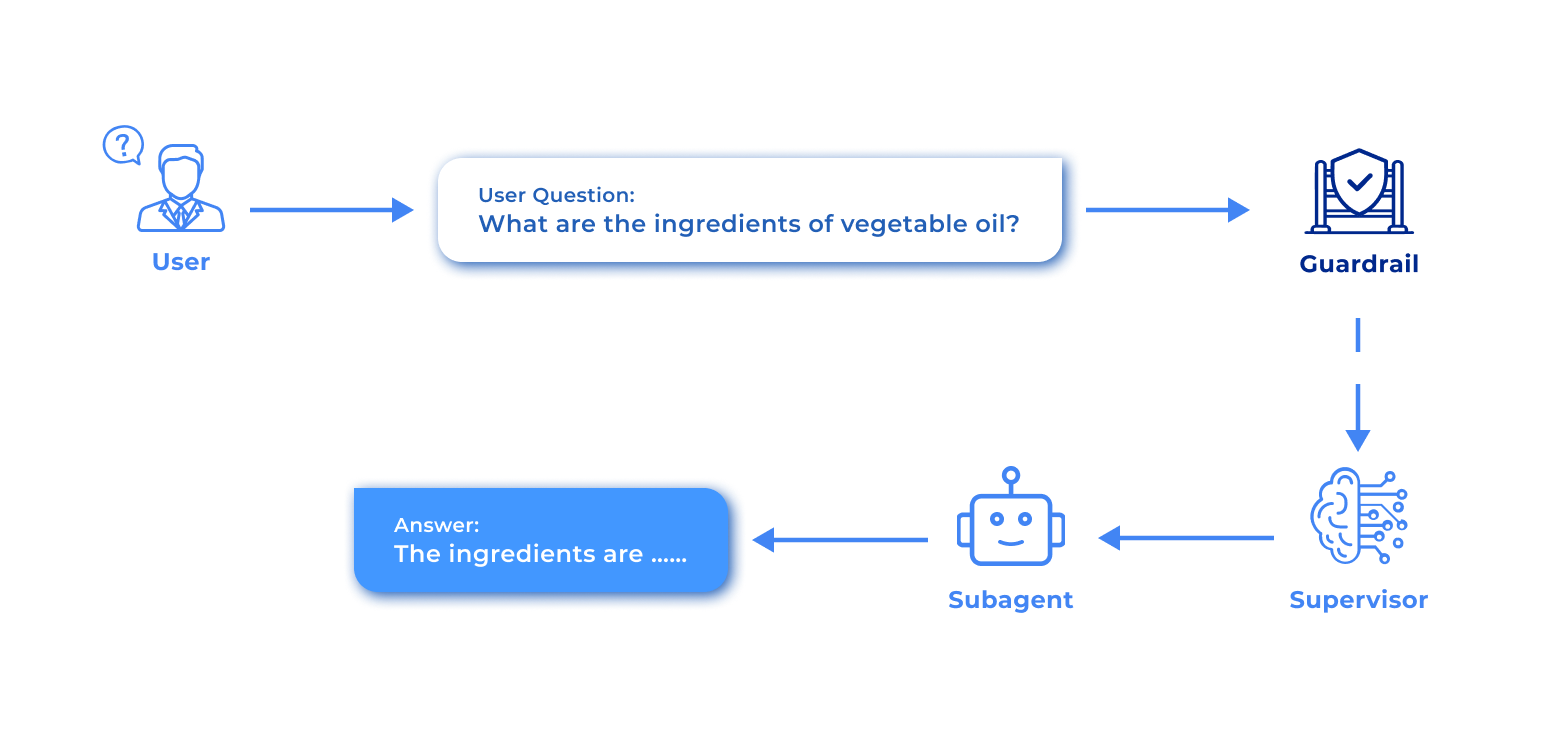
The Guardrail sits strategically between the Application layer and the Multi-Agent System to serve as the bidirectional filter. It works in tandem with LLMOps and Knowledge Retrieval to provide a holistic safety net, validating output and neutralizing malicious attempts such as "jailbreak" or prompt injections.